【Pandas】新型コロナ年齢別死亡者数の棒グラフ作成
新型コロナの年齢別死亡者数を簡単にグラフ化します。
PythonとPandasの練習とメモ。
実行環境
- Android
- Termux(ターミナルアプリ
- Python3.9
- JupyterNotebook
- 外部ライブラリ
- Pandas、matplotlib
目次
- 実行環境
- 目次
- データの入手
- Excelファイルのダウンロード
- ExcelファイルをDataFrameにする
- 必要な行と列を抽出
- インデックス番号を振り直す
- 読み込む所から、もうちょい簡単に
- 棒グラフ作成
- おわりに
データの入手
下記にあるurl_siteは国立社会保障・人口問題研究所のサイトURLです。
その下のurl_dataが年齢別死亡者数を集計したExcelファイルです。こちらをPythonでダウンロードして使います。
Excelファイルのデータは、2020年3月~2021年1月までの毎月の更新日ごとに、当初からの累計データを各シートで表示してあります。※月毎のデータではありません。
この投稿は、最終更新日が2021年1月11日時点での年齢別死亡者数累計が最新シート(一番左にある)になっているファイルのデータに基づいて書いています。
""" ■ データの入手先について
◆ExcelファイルをダウンロードしたサイトのURL 国立社会保障・人口問題研究所 url_site = "http://www.ipss.go.jp/projects/j/Choju/covid19/index.asp"
◆上記のサイトにリンクされた「新型コロナの年齢別死亡者数」のExcelファイルのURL url_data = "http://www.ipss.go.jp/projects/j/Choju/covid19/data/japan_deaths.xlsx"
"""
Excelファイルのダウンロード
ネット上のURLから直接読み込む方法
ExcelファイルはPandasで読み込むのが簡単で楽です。
ネット上のファイルのURLを直接pd.read_excel(ファイルのURL)で読み込んでDataFrameにできます。
注意としては、下記の方法では先頭のシートのみが読み込まれます。全シート取得の方法はこの後で。
url_data = "http://www.ipss.go.jp/projects/j/Choju/covid19/data/japan_deaths.xlsx" import pandas as pd df = pd.read_excel(url_data) # JupyterNotebookに表示 df
| 新型コロナウィルス感染症 死亡者性・年齢階級構造(日本、2021/1/11時点)\n | Unnamed: 1 | Unnamed: 2 | Unnamed: 3 | Unnamed: 4 | Unnamed: 5 | Unnamed: 6 | Unnamed: 7 | Unnamed: 8 | Unnamed: 9 | Unnamed: 10 | Unnamed: 11 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Age Sex Structure of COVID-19 Deaths in Japan(... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 年代 \nAge | 男性 Male | 女性 Female | 非公表 \nNot Disclosed | NaN | for pyramid | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | <10 | 0 | 0 | 0 | NaN | 0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 10s | 0 | 0 | 0 | NaN | 0 | NaN | NaN | NaN | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 71 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 72 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 73 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 74 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 75 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
76 rows × 12 columns
ネット上のExcelファイル(先頭シートのみ)を直接読み込み、Jupyter Notebookに表示できました。
一旦ファイルをダウンロードする方法
上記の方法では実行するごとにネットから読み込み負荷が掛かるので、一旦ファイルをローカルフォルダにダウンロードする方法で行います。
この場合は標準ライブラリのurllib.requestを使って次のようにします。
import urllib.request # ネット上のファイルURL url_data = "http://www.ipss.go.jp/projects/j/Choju/covid19/data/japan_deaths.xlsx" # 保存ファイル名 savename = "japan_deaths.xlsx" # または、urlからファイル名を抜き出す為に #savename = url_data.split("/")[-1] # ダウンロード保存 urllib.request.urlretrieve(url_data, savename)
('japan_deaths.xlsx', <http.client.HTTPMessage at 0x7392b80a90>)
ダウンロード保存されたか確認します。(下記はJupyterNotebookのマジックコマンドを使用)
%ls | grep japan
japan_deaths.xlsx
カレントディレクトリにsavename名で保存されました。
以下、ローカルに保存したファイルを読み込んで使って行きます。
ExcelファイルをDataFrameにする
先頭のシートのみ
先ほどネット上から直接読み込んだ時にやったことと同じです。
【注意】
Excelブックは通常は何枚かのシートで構成されているかと思いますが、単にpd.read_excel()で読み込むだけでは先頭のシートのみしか読み込まれません。
import pandas as pd # カレントディレクトリのExcelファイル filename = "japan_deaths.xlsx" # 読み込んでDataFrameにする(先頭のシートのみ df = pd.read_excel(filename) # JupyterNotebookに表示(省略 #df
ネットから直接読み込んだ時のと同じ表示。
全てのシートを読む場合
read_excel()の引数にsheet_name=Noneを付けますと全てのシートが読み込まれます。
import pandas as pd # カレントディレクトリのExcelファイル filename = "japan_deaths.xlsx" # 読み込んでDataFrameにする(全シート df = pd.read_excel(filename, sheet_name=None) # JupyterNotebookに表示(省略 #df
複数のシートを読み込んだ場合の表示は辞書形式で大量に出力されます。表示は省略しました。
全シートを読み込んだ場合のシート名の取得
上記に書いた通り、DataFrameオブジェクトは辞書形式で表示されます。
- key シート名
- value シート内のデータ
辞書なので、通常通りシート名一覧の取得は辞書.keys()でできます。
# シート名の取得
df.keys()
dict_keys(['210111', '210104', '201221', '201214', '201207', '201130', '201123', '201116', '201109', '201102', '201026', '201019', '201012', '201005', '2009028', '2009022', '2009014', '200907', '200831', '200824', '200817', '200810', '200803', '200727', '200720', '200713', '200706', '200629', '200622', '200615', '200531', '200430', '200331'])
シート名はデータの更新日になっているようです。(実はExcelでカンニング済み)
シート名で指定しシート内容を取得
これも辞書と同じ方法で行う。
# シート名を指定して内容を取得 df["210111"]
| 新型コロナウィルス感染症 死亡者性・年齢階級構造(日本、2021/1/11時点)\n | Unnamed: 1 | Unnamed: 2 | Unnamed: 3 | Unnamed: 4 | Unnamed: 5 | Unnamed: 6 | Unnamed: 7 | Unnamed: 8 | Unnamed: 9 | Unnamed: 10 | Unnamed: 11 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Age Sex Structure of COVID-19 Deaths in Japan(... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 年代 \nAge | 男性 Male | 女性 Female | 非公表 \nNot Disclosed | NaN | for pyramid | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | <10 | 0 | 0 | 0 | NaN | 0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 10s | 0 | 0 | 0 | NaN | 0 | NaN | NaN | NaN | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 71 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 72 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 73 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 74 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 75 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
76 rows × 12 columns
必要な行と列を抽出
ここからようやく使うデータを絞り込みます。
df.iloc[行, 列]で範囲を抽出
# 先頭シートのDataFrame変数を置き換え df = df["210111"] # 適当に目星をつけてしぼる df_s1 = df.iloc[2:17, 0:4] # 表示 df_s1
| 新型コロナウィルス感染症 死亡者性・年齢階級構造(日本、2021/1/11時点)\n | Unnamed: 1 | Unnamed: 2 | Unnamed: 3 | |
|---|---|---|---|---|
| 2 | 年代 \nAge | 男性 Male | 女性 Female | 非公表 \nNot Disclosed |
| 3 | <10 | 0 | 0 | 0 |
| 4 | 10s | 0 | 0 | 0 |
| 5 | 20s | 1 | 0 | 0 |
| 6 | 30s | 7 | 2 | 0 |
| 7 | 40s | 18 | 9 | 0 |
| 8 | 50s | 84 | 11 | 1 |
| 9 | 60s | 237 | 52 | 2 |
| 10 | 70s | 588 | 230 | 5 |
| 11 | 80s | 844 | 574 | 7 |
| 12 | 90+ | 258 | 423 | 4 |
| 13 | 小計 \nSubtotal | 2037 | 1301 | 19 |
| 14 | 高齢者 \nOld Person | 28 | 17 | 140 |
| 15 | 非公表 \nNot Disclosed | 25 | 10 | 537 |
| 16 | 合計 \nTotal | 2090 | 1328 | 696 |
下の4行は集計行で不要、「年代」「男性」「女性」の行も不要だが、これをヘッダーにする。
DataFrameのヘッダー行を変更
不要な行を取り除き、
DataFrameのヘッダー行(項目名のある行)を変更します。
「年代」「男性」「女性」とかある行をヘッダーにします。
# 不要な行を取り除く df_s1.iloc[1:-4, :]
| 新型コロナウィルス感染症 死亡者性・年齢階級構造(日本、2021/1/11時点)\n | Unnamed: 1 | Unnamed: 2 | Unnamed: 3 | |
|---|---|---|---|---|
| 3 | <10 | 0 | 0 | 0 |
| 4 | 10s | 0 | 0 | 0 |
| 5 | 20s | 1 | 0 | 0 |
| 6 | 30s | 7 | 2 | 0 |
| 7 | 40s | 18 | 9 | 0 |
| 8 | 50s | 84 | 11 | 1 |
| 9 | 60s | 237 | 52 | 2 |
| 10 | 70s | 588 | 230 | 5 |
| 11 | 80s | 844 | 574 | 7 |
| 12 | 90+ | 258 | 423 | 4 |
# ヘッダー行の変更 df_s1.columns = df_s1.iloc[0] # データフレームの表示 df_n = df_s1.iloc[1:-4,:] df_n
| 2 | 年代 \nAge | 男性 Male | 女性 Female | 非公表 \nNot Disclosed |
|---|---|---|---|---|
| 3 | <10 | 0 | 0 | 0 |
| 4 | 10s | 0 | 0 | 0 |
| 5 | 20s | 1 | 0 | 0 |
| 6 | 30s | 7 | 2 | 0 |
| 7 | 40s | 18 | 9 | 0 |
| 8 | 50s | 84 | 11 | 1 |
| 9 | 60s | 237 | 52 | 2 |
| 10 | 70s | 588 | 230 | 5 |
| 11 | 80s | 844 | 574 | 7 |
| 12 | 90+ | 258 | 423 | 4 |
インデックス番号を振り直す
データフレーム.reset_index()でインデックスを振り直す。
引数にdrop=Trueを付けると旧インデックス行が削除できる。違いが分かるよう2種類行う。
# インデックス番号の振り直し(旧インデックス残る df_renew = df_n.reset_index() # 表示 df_renew
| 2 | index | 年代 \nAge | 男性 Male | 女性 Female | 非公表 \nNot Disclosed |
|---|---|---|---|---|---|
| 0 | 3 | <10 | 0 | 0 | 0 |
| 1 | 4 | 10s | 0 | 0 | 0 |
| 2 | 5 | 20s | 1 | 0 | 0 |
| 3 | 6 | 30s | 7 | 2 | 0 |
| 4 | 7 | 40s | 18 | 9 | 0 |
| 5 | 8 | 50s | 84 | 11 | 1 |
| 6 | 9 | 60s | 237 | 52 | 2 |
| 7 | 10 | 70s | 588 | 230 | 5 |
| 8 | 11 | 80s | 844 | 574 | 7 |
| 9 | 12 | 90+ | 258 | 423 | 4 |
# インデックス番号の振り直し(旧インデックス削除 df_renew2 = df_n.reset_index(drop=True) # 表示 df_renew2
| 2 | 年代 \nAge | 男性 Male | 女性 Female | 非公表 \nNot Disclosed |
|---|---|---|---|---|
| 0 | <10 | 0 | 0 | 0 |
| 1 | 10s | 0 | 0 | 0 |
| 2 | 20s | 1 | 0 | 0 |
| 3 | 30s | 7 | 2 | 0 |
| 4 | 40s | 18 | 9 | 0 |
| 5 | 50s | 84 | 11 | 1 |
| 6 | 60s | 237 | 52 | 2 |
| 7 | 70s | 588 | 230 | 5 |
| 8 | 80s | 844 | 574 | 7 |
| 9 | 90+ | 258 | 423 | 4 |
一番左上の「2」が気になるね?消しておくか。
データフレーム.columns.nameの値がそこに入っている。
# カラム名を抽出 print("カラム\n",df_renew2.columns) print("\nカラムの名前\n",df_renew2.columns.name)
カラム
Index(['年代 \nAge', '男性 Male', '女性 Female', '非公表 \nNot Disclosed'], dtype='object', name=2)
カラムの名前
2
# カラムの名前を空に変更 df_renew2.columns.name = "" # データフレーム表示 df_renew2
| 年代 \nAge | 男性 Male | 女性 Female | 非公表 \nNot Disclosed | |
|---|---|---|---|---|
| 0 | <10 | 0 | 0 | 0 |
| 1 | 10s | 0 | 0 | 0 |
| 2 | 20s | 1 | 0 | 0 |
| 3 | 30s | 7 | 2 | 0 |
| 4 | 40s | 18 | 9 | 0 |
| 5 | 50s | 84 | 11 | 1 |
| 6 | 60s | 237 | 52 | 2 |
| 7 | 70s | 588 | 230 | 5 |
| 8 | 80s | 844 | 574 | 7 |
| 9 | 90+ | 258 | 423 | 4 |
読み込む所から、もうちょい簡単に
Pandasの練習ということで、無駄なことをやってきましたが、もうちょい簡単にやります。
import pandas as pd filename = "japan_deaths.xlsx" df = pd.read_excel(filename, header=3) df
| 年代 \nAge | 男性 Male | 女性 Female | 非公表 \nNot Disclosed | Unnamed: 4 | for pyramid | Unnamed: 6 | Unnamed: 7 | Unnamed: 8 | Unnamed: 9 | Unnamed: 10 | Unnamed: 11 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | <10 | 0.0 | 0.0 | 0.0 | NaN | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | 10s | 0.0 | 0.0 | 0.0 | NaN | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 20s | 1.0 | 0.0 | 0.0 | NaN | -1.0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | 30s | 7.0 | 2.0 | 0.0 | NaN | -7.0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 40s | 18.0 | 9.0 | 0.0 | NaN | -18.0 | NaN | NaN | NaN | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 68 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 69 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 70 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 71 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 72 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
73 rows × 12 columns
# 絞り込み df_use = df.iloc[0:13,0:4] df_use
| 年代 \nAge | 男性 Male | 女性 Female | 非公表 \nNot Disclosed | |
|---|---|---|---|---|
| 0 | <10 | 0.0 | 0.0 | 0.0 |
| 1 | 10s | 0.0 | 0.0 | 0.0 |
| 2 | 20s | 1.0 | 0.0 | 0.0 |
| 3 | 30s | 7.0 | 2.0 | 0.0 |
| 4 | 40s | 18.0 | 9.0 | 0.0 |
| 5 | 50s | 84.0 | 11.0 | 1.0 |
| 6 | 60s | 237.0 | 52.0 | 2.0 |
| 7 | 70s | 588.0 | 230.0 | 5.0 |
| 8 | 80s | 844.0 | 574.0 | 7.0 |
| 9 | 90+ | 258.0 | 423.0 | 4.0 |
| 10 | 小計 \nSubtotal | 2037.0 | 1301.0 | 19.0 |
| 11 | 高齢者 \nOld Person | 28.0 | 17.0 | 140.0 |
| 12 | 非公表 \nNot Disclosed | 25.0 | 10.0 | 537.0 |
# 更に絞り込み df_use = df_use.iloc[0:-3, :] df_use
| 年代 \nAge | 男性 Male | 女性 Female | 非公表 \nNot Disclosed | |
|---|---|---|---|---|
| 0 | <10 | 0.0 | 0.0 | 0.0 |
| 1 | 10s | 0.0 | 0.0 | 0.0 |
| 2 | 20s | 1.0 | 0.0 | 0.0 |
| 3 | 30s | 7.0 | 2.0 | 0.0 |
| 4 | 40s | 18.0 | 9.0 | 0.0 |
| 5 | 50s | 84.0 | 11.0 | 1.0 |
| 6 | 60s | 237.0 | 52.0 | 2.0 |
| 7 | 70s | 588.0 | 230.0 | 5.0 |
| 8 | 80s | 844.0 | 574.0 | 7.0 |
| 9 | 90+ | 258.0 | 423.0 | 4.0 |
これで、よし。
棒グラフ作成
- 「男性」「女性」「非公表」のそれぞれのグラフ
- 1を積み重ねたグラフ
の2つを描く。
データは、
- x軸データ : 「年代」列
- y軸データ :
- 「男性」列
- 「女性」列
- 「非公表」列
# x軸用 x = df_use.iloc[:,0] # y軸用 y_m = df_use.iloc[:,1] #男性 y_f = df_use.iloc[:, 2] # 女性 y_un = df_use.iloc[:, 3] # 非公表
データが用意できたので、グラフを描いていく。
import matplotlib.pyplot as plt plt.bar(x,y_m, label="male", color="blue") plt.show() plt.bar(x,y_f, label="female", color="red") plt.title("female") plt.show() plt.bar(x,y_un, label="undisclosed", color="green") plt.legend() plt.show()
↑自動保存された画像はpngで軸が消えている。
plt.show()の上にplt.savefig("画像保存名.jpg")を書き保存し直したjpg画像のグラフ
↓
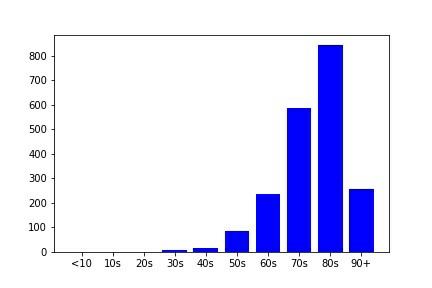

↑自動保存のpng画像
↓jpg画像


↑自動保存のpng画像
↓jpgで保存した画像

titleやlegendの付け具合が分かるようにした。
【追記】グラフ画像の保存plt.savefig("保存名")を書かないと、標準ではpngで自動保存される。
plt.show()の上にplt.savefig()は書くこと。さもないとグラフの描かれていない画像が保存されてしまう。追記終わり
高齢者が多い。新型コロナでなくとも、死亡者のグラフはこのような形になっているだろう。
積み重ねた棒グラフ
bottomと書いた部分がある。これを書かないと積み重ねたグラフにはなるものの、数値的におかしいグラフになった。理由は不明。
plt.bar(x,y_m, label="male", color="blue") plt.bar(x,y_f, label="female", color="red", bottom=y_m) plt.bar(x,y_un, label="fumei", color="green",bottom=y_m) plt.grid() plt.legend() plt.show()

↑png
↓jpg

一番多い年代でも1400人ほど。餅詰まらせるのと張り合うレベル。こんなので騒いで100兆円以上使うとか、だいぶん頭おかしい。
おわりに
途中無駄なことをして長くなった。
コロナの騒ぎ過ぎ感。
日本全体の超過死亡者数でも2020年は2019年より減っているという。もし感染の確認がなされずコロナのデータに載らなかった死者が爆増していたら恐怖すべきだとは思うが、それもない。
政治やマスコミに殺されるぐらいならコロナに殺られた方がマシだ。