【AndroidアプリGoogleマップ】手動で座標を取得する方法
AndroidアプリのGoogleマップ上で、座標を 手動で 取得する方法のメモ。忘れない内に。
プログラミングのブログで「手動」とはだいぶんアホな投稿ですが、Googleマップ座標をプログラムで取得するには、GoogleマップAPIを使えばできるのだろう。なんかAPI登録など必要らしく面倒だ。
(今回は)大量に取得するわけでもないので手動で行います。(手動の方が面倒そうだが)
意外とムズい。簡単に座標をコピーできるようになっていない。
手順
大まかにこんな手順。
- Googleマップアプリで「オフラインマップ」を前もってダウンロードしておく。(詳細割愛)
- オフラインマップのデータ容量は大きい(1つの都道府県単位で約100MB前後ほど)。無料でできる。
- オフラインマップのデータ容量は大きい(1つの都道府県単位で約100MB前後ほど)。無料でできる。
- オフラインで、Googleマップアプリを開く。
- 必ずオフラインで。オンラインだと上手くいかない。
- 必ずオフラインで。オンラインだと上手くいかない。
- Googleマップの検索窓でキーワード検索する。
- オフラインマップ をダウンロード済みなら、オフラインでも検索できる。
- オフラインマップ をダウンロード済みなら、オフラインでも検索できる。
- 検索結果の候補が出たらタップ。
- 検索場所にピンが差さっている筈。
- 検索場所にピンが差さっている筈。
- ピンの場所を拡大し、ピンポイントを長押しする。
- 長押しした場所に新しくピンが差される。微妙にズレる…
- 長押しした場所に新しくピンが差される。微妙にズレる…
- 検索窓に座標が表示される。
- 検索窓をタップ。
- 【注意】この時オンラインだと、座標が住所に変換されて表示され、コピーできなくなる。
- 検索窓を再びタップすると通常の「コピー 貼り付け すべて選択」みたいな表示が出るので、コピーする。
大まかな手順は以上。「オフライン」で行うこと。
図解で手順
佐賀県みやき町「物部神社」の座標の取得例。近々行ってみたいと思っておりまして。
- 「オフライン」で検索
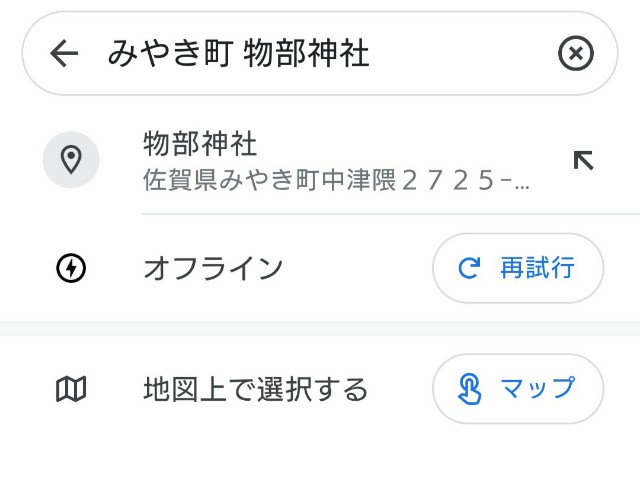
- 検索結果が表示される。
出ない場所もあるかも。そんな時は、一旦オンラインで検索し、オンライン に切り替える。
- 地図を拡大し、ピンの場所を長押しする
長押しした場所に新しくピンが出る。大体合わさるようになってれば良いでしょう。微妙にズレてるが、手動の限界。

検索窓に、座標が表示された。
- 検索窓をタップする

通常のテキスト編集のときと同じように、コピーできる。以上。
(失敗例)オンラインで行うと…
上と同じ行程を オンライン でやります。上手くいかない例。
太宰府の「竈門神社」の例で。そのうち行こうかと。
- 場所を検索する

検索窓に座標が出たので、タップする。
- 座標の表示がすぐさま住所に変わる

座標のコピーが出来ない。
(復活編)オンラインに切り替えると
オンラインだと座標が住所に切り替わってしまい、コピー出来なかった。
しかしそこで オフライン にして、再び長押しタップをすればコピーできる。

なお、場所が分かっていれば、検索の行程は省略して構わない。長押ししてピンが刺さる所の座標が取得できる。
手動の座標取得はオフラインで。
geocoding.jp で取得できなかった座標の手動取得メモでした。
以上。