Numpyだけで回帰分析その6。ワイン成分の重回帰分析実践
Numpyだけで回帰分析その6。
実戦投入!ワインをスマホに飲ませるの巻![]()
実行環境
Androidスマホ
termux
Python3.8
JupyterNotebook
スマホで機械学習をやろうとする無茶な試み。termuxからscipyやscikit-learnがinstallできていない為、Numpyだけで回帰分析している。
こんな無駄なことしたくなくば直ちに立ち去り、PCか、GoogleColaroratoryか、pydroid3か、pythonista3(sklearn動くっけ?)を使うべしよ。
目次
準備するもの
使用するデータ
今回は機械学習でよく使われるワインの成分データのCSVファイルをダウンロードして使います。
http://pythondatascience.plavox.info/wp-content/uploads/2016/07/winequality-red.csv使用するPythonライブラリ
CSVファイル読み込み用にPandas、その他の作業は全てNumpyでやります。
これ等が動く環境の準備が要ります。JupyterNotebookを使って実行しながらブログ記事を兼ねて書いております。
変数などの重複や書き損じ等、満載か。データのダウンロード、重回帰分析の結果を照らし合わせる目的や参考資料で
scikit-learn で線形回帰 (単回帰分析・重回帰分析) – Python でデータサイエンス
を参照させて頂きますた。ありがとうございます。
PandasでCSVファイルの読み込み
とりあえず読んでおくか。
import pandas as pd # CSVファイル data_file = "winequality-red.csv" # PandasでCSVファイルの読み込み df = pd.read_csv(data_file) # DataFrameの上5行表示 df.head()
| fixed acidity;"volatile acidity";"citric acid";"residual sugar";"chlorides";"free sulfur dioxide";"total sulfur dioxide";"density";"pH";"sulphates";"alcohol";"quality" | |
|---|---|
| 0 | 7.4;0.7;0;1.9;0.076;11;34;0.9978;3.51;0.56;9.4;5 |
| 1 | 7.8;0.88;0;2.6;0.098;25;67;0.9968;3.2;0.68;9.8;5 |
| 2 | 7.8;0.76;0.04;2.3;0.092;15;54;0.997;3.26;0.65;... |
| 3 | 11.2;0.28;0.56;1.9;0.075;17;60;0.998;3.16;0.58... |
| 4 | 7.4;0.7;0;1.9;0.076;11;34;0.9978;3.51;0.56;9.4;5 |
;で区切られている。やり直し。
import pandas as pd # CSVファイル data_file = "winequality-red.csv" # PandasでCSVファイルの読み込み df = pd.read_csv( data_file, delimiter =';' ) # DataFrameの上5行表示 df.head()
| fixed acidity | volatile acidity | citric acid | residual sugar | chlorides | free sulfur dioxide | total sulfur dioxide | density | pH | sulphates | alcohol | quality | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7.4 | 0.70 | 0.00 | 1.9 | 0.076 | 11.0 | 34.0 | 0.9978 | 3.51 | 0.56 | 9.4 | 5 |
| 1 | 7.8 | 0.88 | 0.00 | 2.6 | 0.098 | 25.0 | 67.0 | 0.9968 | 3.20 | 0.68 | 9.8 | 5 |
| 2 | 7.8 | 0.76 | 0.04 | 2.3 | 0.092 | 15.0 | 54.0 | 0.9970 | 3.26 | 0.65 | 9.8 | 5 |
| 3 | 11.2 | 0.28 | 0.56 | 1.9 | 0.075 | 17.0 | 60.0 | 0.9980 | 3.16 | 0.58 | 9.8 | 6 |
| 4 | 7.4 | 0.70 | 0.00 | 1.9 | 0.076 | 11.0 | 34.0 | 0.9978 | 3.51 | 0.56 | 9.4 | 5 |
あっさり読み込み成功。Pandasはできる子。
データの基本情報の取得
読み込めたので、中身の情報を適当に取得する。
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1599 entries, 0 to 1598
Data columns (total 12 columns):
fixed acidity 1599 non-null float64
volatile acidity 1599 non-null float64
citric acid 1599 non-null float64
residual sugar 1599 non-null float64
chlorides 1599 non-null float64
free sulfur dioxide 1599 non-null float64
total sulfur dioxide 1599 non-null float64
density 1599 non-null float64
pH 1599 non-null float64
sulphates 1599 non-null float64
alcohol 1599 non-null float64
quality 1599 non-null int64
dtypes: float64(11), int64(1)
memory usage: 150.0 KB
df.describe()
| fixed acidity | volatile acidity | citric acid | residual sugar | chlorides | free sulfur dioxide | total sulfur dioxide | density | pH | sulphates | alcohol | quality | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 1599.000000 | 1599.000000 | 1599.000000 | 1599.000000 | 1599.000000 | 1599.000000 | 1599.000000 | 1599.000000 | 1599.000000 | 1599.000000 | 1599.000000 | 1599.000000 |
| mean | 8.319637 | 0.527821 | 0.270976 | 2.538806 | 0.087467 | 15.874922 | 46.467792 | 0.996747 | 3.311113 | 0.658149 | 10.422983 | 5.636023 |
| std | 1.741096 | 0.179060 | 0.194801 | 1.409928 | 0.047065 | 10.460157 | 32.895324 | 0.001887 | 0.154386 | 0.169507 | 1.065668 | 0.807569 |
| min | 4.600000 | 0.120000 | 0.000000 | 0.900000 | 0.012000 | 1.000000 | 6.000000 | 0.990070 | 2.740000 | 0.330000 | 8.400000 | 3.000000 |
| 25% | 7.100000 | 0.390000 | 0.090000 | 1.900000 | 0.070000 | 7.000000 | 22.000000 | 0.995600 | 3.210000 | 0.550000 | 9.500000 | 5.000000 |
| 50% | 7.900000 | 0.520000 | 0.260000 | 2.200000 | 0.079000 | 14.000000 | 38.000000 | 0.996750 | 3.310000 | 0.620000 | 10.200000 | 6.000000 |
| 75% | 9.200000 | 0.640000 | 0.420000 | 2.600000 | 0.090000 | 21.000000 | 62.000000 | 0.997835 | 3.400000 | 0.730000 | 11.100000 | 6.000000 |
| max | 15.900000 | 1.580000 | 1.000000 | 15.500000 | 0.611000 | 72.000000 | 289.000000 | 1.003690 | 4.010000 | 2.000000 | 14.900000 | 8.000000 |
print(df.shape, df.size)
(1599, 12) 19188
df.isnull().sum()
fixed acidity 0
volatile acidity 0
citric acid 0
residual sugar 0
chlorides 0
free sulfur dioxide 0
total sulfur dioxide 0
density 0
pH 0
sulphates 0
alcohol 0
quality 0
dtype: int64
- 行で1599本のワインデータ
- 列で12項目
- 最終列は型int、その他float型
- 欠損値無し
ワインを11項目の成分から品質で分類したことを示す表になってるんですかね。
- 品質を目的変数
- 11項目の成分を説明変数
で重回帰分析してOKなんだろうか?
「クラスタで分類とかそんなんじゃないの?」
と思いつつ、それでやってみる。
Numpy linalg.lstsqのおでまし
炸裂していただこう。
import numpy as np # 目的変数 最終列(quality) y = df.iloc[:, -1].values.reshape(-1,1) y
array([[5],
[5],
[5],
...,
[6],
[5],
[6]])
# 説明変数 最終列以外 x = df.iloc[:, 0:11].values x
array([[ 7.4 , 0.7 , 0. , ..., 3.51 , 0.56 , 9.4 ],
[ 7.8 , 0.88 , 0. , ..., 3.2 , 0.68 , 9.8 ],
[ 7.8 , 0.76 , 0.04 , ..., 3.26 , 0.65 , 9.8 ],
...,
[ 6.3 , 0.51 , 0.13 , ..., 3.42 , 0.75 , 11. ],
[ 5.9 , 0.645, 0.12 , ..., 3.57 , 0.71 , 10.2 ],
[ 6. , 0.31 , 0.47 , ..., 3.39 , 0.66 , 11. ]])
# 定数項を二次元列ベクトルで作成 # 全行オール1 ones = np.ones(df.shape[0]).reshape(-1,1) ones
array([[1.],
[1.],
[1.],
...,
[1.],
[1.],
[1.]])
# 説明変数最終列に定数項を結合
x = np.hstack([x, ones])
x
array([[ 7.4 , 0.7 , 0. , ..., 0.56 , 9.4 , 1. ],
[ 7.8 , 0.88 , 0. , ..., 0.68 , 9.8 , 1. ],
[ 7.8 , 0.76 , 0.04 , ..., 0.65 , 9.8 , 1. ],
...,
[ 6.3 , 0.51 , 0.13 , ..., 0.75 , 11. , 1. ],
[ 5.9 , 0.645, 0.12 , ..., 0.71 , 10.2 , 1. ],
[ 6. , 0.31 , 0.47 , ..., 0.66 , 11. , 1. ]])
準備完了した。linalg.lstsq()マシーンに係数作成をお願いします。
# 線形代数最小2乗法による係数作成 coef = np.linalg.lstsq(x, y, rcond=None) coef
(array([[ 2.49905527e-02],
[-1.08359026e+00],
[-1.82563948e-01],
[ 1.63312698e-02],
[-1.87422516e+00],
[ 4.36133331e-03],
[-3.26457970e-03],
[-1.78811638e+01],
[-4.13653144e-01],
[ 9.16334413e-01],
[ 2.76197699e-01],
[ 2.19652084e+01]]),
array([666.41070039]),
12,
array([2.42243375e+03, 3.77646196e+02, 2.61834800e+02, 6.20095782e+01,
5.35066741e+01, 1.41225264e+01, 7.56201355e+00, 5.96332987e+00,
4.07073095e+00, 1.72868243e+00, 1.28895532e+00, 2.13989307e-02]))
追記
数値がこの後に出てくる物と違ってますね。実行ミスかな?
偏回帰係数の確認
重回帰分析で得られる多項式の各係数を偏回帰係数というのだそうだ。
次のサイトでは同じCSVファイルのワイン成分データを使ってsklearnで重回帰分析をされている。我が係数をそれと照らし合わせてみます。
[https://pythondatascience.plavox.info/scikit-learn/%E7%B7%9A%E5%BD%A2%E5%9B%9E%E5%B8%B0:title]
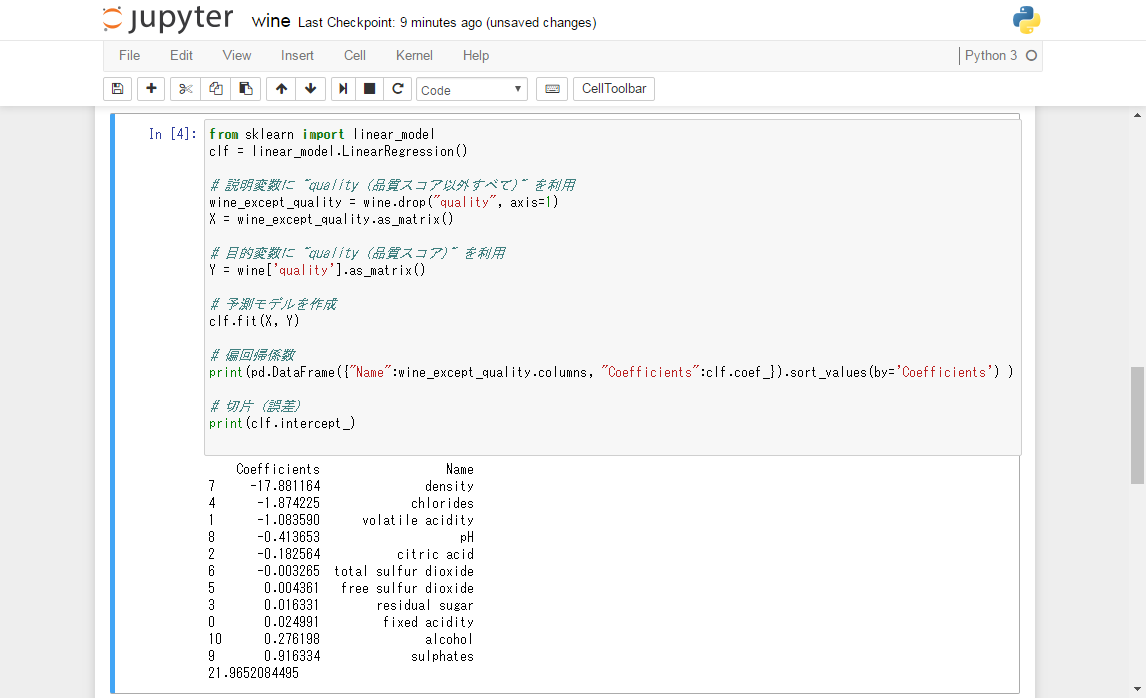
ページから抜粋
sklearnで算出された係数と回帰式は、つぎのようになっている。
[quality] = -17.881164 × [density] + -1.874225 × [chlorides] + -1.083590 × [volatile acidity] + -0.413653 × [pH] + -0.182564 × [citric acid] + -0.003265 × [total sulfur dioxide] + 0.004361 × [free sulfur dioxide] + 0.016331 × [residual sugar] + 0.024991 × [fixed acidity] + 0.276198 × [alcohol] + 0.916334 × [sulphates] + 21.9652084495
そして下が我が酔っ払いスマホがNumpyだけで出した係数。
ソートで上と同じように並び替えました。
# 算出した偏回帰係数を1次元変換しsort sorted_coef = np.sort(coef[0].ravel()) # 順に表示 for i in sorted_coef : print(i)
-17.8811638325047
-1.8742251580991092
-1.0835902586934505
-0.41365314382173
-0.18256394841071127
-0.0032645797030711465
0.004361333309095383
0.016331269765480563
0.024990552671676984
0.27619769922687587
0.9163344127211389
21.965208449457194
同じだ!素晴らしい!