【Pandas】任意の教科数と人数の成績表から学力を平均的に指定数でクラス分けする
成績表をもとに学力が平均的になるようにグループ分けする最終回
成績表をもとに学力が平均化するようにグループ分けするシリーズ、今回は最終回。
任意の教科数と人数の入った成績表を指定クラス数に分け、バラツキ最小と最大のクラス分けを返す関数を作る。
【実行環境】
- Windows10
- WSL:Ubuntu:Anaconda4.10.1
- Python3.8.10
- Jupyter Notebook6.4.0
- 使用ライブラリ
- numpy1.20.2、pandas1.2.4、matplotlib3.3.4、scikit-learn0.24.2、japanize-matplotlib(グラフの日本語表示用)
Anacondaをインストールすると今回使うライブラリは最初から全部入っているようなので(japanize-matplotlib以外は)インストー ルは不要です。
入ってないようならcondaやpipで
$ pip install notebook numpy pandas matplotlib sklearn japanize-matplotlib
など環境に合わせてインストールしておきます。
【クラス分けの方法について】
方法の手順として、
- 学年全員分の成績表データフレームを読み込む
- そのデータフレームをランダムにシャッフルして、指定グループ数に分け、クラス番号を割り振る
- クラスごとで教科や合計等の平均値を出す
- クラス間で平均値の標準偏差を出しバラツキを見る
- クラス間の教科や合計の総合的な標準偏差を算出する
- 2~5の手順を指定回繰り返し、ランダム生成した全てのデータフレームと総合的な標準偏差を保存する
- 最も平均的にグループ分けしたデータフレームを出力する
成績表を生成する
成績表の例として前回までと同様、国・数・社・理・英、各100点満点のテストの成績表を100人分、一様分布のランダムな値で生成します。
# 成績表の生成 import numpy as np import pandas as pd import matplotlib.pyplot as plt import japanize_matplotlib np.random.seed(0) # ランダムの固定 # 100行5列でランダムな配列を生成 arr = np.random.randint(0,101,500).reshape(100, 5) # 成績表データフレームの作成 col = ["国語", "数学", "社会", "理科", "英語"] df = pd.DataFrame(arr, columns=col) df
| 国語 | 数学 | 社会 | 理科 | 英語 | |
|---|---|---|---|---|---|
| 0 | 44 | 47 | 64 | 67 | 67 |
| 1 | 9 | 83 | 21 | 36 | 87 |
| 2 | 70 | 88 | 88 | 12 | 58 |
| 3 | 65 | 39 | 87 | 46 | 88 |
| 4 | 81 | 37 | 25 | 77 | 72 |
| ... | ... | ... | ... | ... | ... |
| 95 | 36 | 68 | 80 | 47 | 10 |
| 96 | 94 | 91 | 43 | 63 | 31 |
| 97 | 20 | 70 | 9 | 60 | 91 |
| 98 | 35 | 83 | 76 | 18 | 74 |
| 99 | 98 | 97 | 43 | 3 | 12 |
100 rows × 5 columns
関数の作成
上記の手順を処理する関数を作っていきます。
個人ごとに合計点を算出し、順位付けを行う関数
上記のような形式の成績表を引数に与えると、合計点を個人ごとに算出し、その値の大きい順から順位付けを行う関数。
def ranking(df): '''元の成績表から個人ごとに合計点を算出し、その値の大きい順から順位付けを行います。 「合計」「順位」列を追加します。 ''' # コピー ranked_df = df.copy() # 合計点算出と合計列追加 ranked_df['合計'] = df.sum(axis=1) # 合計点順位列の追加 (降順で順位付け、同一順位は最小値を取る、順位を整数値に変換) ranked_df['順位'] = ranked_df['合計'].rank(method='min', ascending=False).astype('int') return ranked_df
指定の個数にグループ分けする関数
上記の関数で生成された成績表を行でランダムにシャッフルし、指定個数num個のグループに分け、クラス番号を割り振ります。
def shuffle_df(ranked_df, num): '''成績表を基にランダムで指定グループ数にクラス分けします。 「クラス番号」列を追加します。 ''' # 成績表dfの行をランダムに入れ替える df_shuffled = ranked_df.sample(frac=1) # 乱数固定なし # 指定グループ数に分割し、クラス番号列を追加 group_name_list = np.array_split(np.zeros(df_shuffled.shape[0]), num) # 成績表の行数個のゼロ配列をnumグループに分割 for group, n in zip(group_name_list, [i for i in range(num)]): # 各グループの要素をグループ名に置換 group.fill(n) group_name_arr = np.hstack(group_name_list) # 結合して1次元配列にする df_shuffled['クラス番号'] = group_name_arr.astype(np.int64) # データフレームに列追加 return df_shuffled
クラスごと平均点、クラス間標準偏差、全体的な標準偏差を算出する関数
↑のデータフレームに対して、下記の3つの戻り値を返す関数を作ります。
- Pandasの
groupby().mean()メソッドでクラス別の平均点データフレーム - 平均点データフレームに対し、
std()メソッドで標準偏差を算出 - 総合的なばらつきを見るために、クラス間の標準偏差を算出
def output_std(_df): '''ランダムにクラス分けしたデータフレーム保存リストから、 ・クラスごとの平均値データフレーム、 ・クラス間の標準偏差、 ・総合的な標準偏差 の3つを格納したリストを返します。''' # クラスごとの平均値データフレーム mean_df = _df.groupby('クラス番号').mean() # 平均値のクラス間標準偏差 mean_std = _df.groupby('クラス番号').mean().std() # 総合的な標準偏差 total_std = _df.groupby('クラス番号').mean().std().std() return [mean_df, mean_std, total_std]
クラスごとの平均値積み上げ棒グラフ関数
確認用で、クラスごとの平均値データフレームから積み上げ棒グラフを作成する関数を作ります。
各教科ごと平均値が積み上がったクラスごとの棒グラフができます。
def draw_graph(mean_df, save_fname='クラスごと平均値積み上げ棒グラフ'): '''クラスごとの平均値データフレームから積み上げ棒グラフを描画します。''' fig, ax = plt.subplots(figsize=(15, 8), facecolor='w') mean_df.plot.bar(y=mean_df.columns[:-2], ax=ax, alpha=1.0, stacked=True) plt.xticks(rotation=0, size=16) plt.title(save_fname, size=15) plt.xlabel('クラス名') plt.ylabel('平均値・合計値') plt.grid() plt.savefig(save_fname+'.jpg') plt.show()
複数のデータフレームをリストに保存する
データフレームのオブジェクトをリストに次々と追加していく。
# 複数のデータフレームをリストに追加・保存する関数 def save_dfs(df_lst, random_df): '''複数のデータフレームをリストに追加・保存します。''' df_lst.append(random_df) return df_lst
メイン関数
全体を指定の分割グループ数に分けます。
def main(df, split_num=4): ''' 成績表dfをランダムでシャッフルし、指定のグループ数に分けることを100回行います。 全てのグループ分けを保存しリストにします。 その中からバラツキ最小なベストクラス編成とバラツキ最大のワーストクラス編成をリストで返します。 戻り値:リスト [ [ベストクラス編成済成績表df、ベストクラス編成平均値df、最小標準偏差], [ワーストクラス編成済成績表df、ワースト平均値df、最大標準偏差] ] ''' # 生成データフレーム保存用リスト all_lst = [] # クラス分けをtrial回繰り返す for i in range(100): df_each_lst = [] # 試行ごとのデータ保存用リスト ranked_df = ranking(df) # 合計列と順位列の追加 df_shuffled_class = shuffle_df(ranked_df, split_num) # ランダムにクラス分け std_lst = output_std(df_shuffled_class) # 平均値・標準偏差の算出 # シャッフルされた試行ごとのデータフレームと標準偏差の保存 each_lst = save_dfs(df_each_lst, df_shuffled_class) each_lst.extend(std_lst) # 全生成データの保存 all_lst.append(df_each_lst) # 最もバラツキの少ない標準偏差 min_std = np.min([i[3] for i in all_lst]) # バラツキ最小の試行回インデックス min_index = [i[3] for i in all_lst].index(min_std) # バラツキ最小の平均点データフレーム min_std_df = all_lst[min_index][1] # バラツキ最小のクラス分け best_df = all_lst[min_index][0] # 最もバラツキの大きい標準偏差 max_std = np.max([i[3] for i in all_lst]) # バラツキ最大の試行回インデックス max_index = [i[3] for i in all_lst].index(max_std) # バラツキ最大の平均点データフレーム max_std_df = all_lst[max_index][1] # バラツキ最大のクラス分け worst_df = all_lst[max_index][0] return [[best_df, min_std_df, min_std], [worst_df, max_std_df, max_std]]
実行
5教科の成績表をもとに5クラスに編成する。
最もバラツキのない編成と、最もいびつな編成を取り出す。
# 実行 data = main(df, split_num=5) # 表示 print('最小標準偏差',data[0][2]) print('最大標準偏差',data[1][2])
最小標準偏差 1.2918541020351155
最大標準偏差 7.15542116374981
- ベストなクラス分け
# バラツキ最小のベストなクラス分け data[0][0]
| 国語 | 数学 | 社会 | 理科 | 英語 | 合計 | 順位 | クラス番号 | |
|---|---|---|---|---|---|---|---|---|
| 80 | 51 | 30 | 53 | 58 | 43 | 235 | 62 | 0 |
| 36 | 96 | 4 | 67 | 11 | 86 | 264 | 38 | 0 |
| 64 | 92 | 43 | 83 | 49 | 41 | 308 | 14 | 0 |
| 26 | 35 | 94 | 67 | 82 | 46 | 324 | 6 | 0 |
| 1 | 9 | 83 | 21 | 36 | 87 | 236 | 60 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 76 | 5 | 0 | 8 | 79 | 79 | 171 | 91 | 4 |
| 83 | 80 | 26 | 35 | 58 | 49 | 248 | 50 | 4 |
| 79 | 91 | 51 | 99 | 18 | 34 | 293 | 23 | 4 |
| 22 | 50 | 36 | 34 | 48 | 93 | 261 | 41 | 4 |
| 78 | 45 | 26 | 74 | 52 | 49 | 246 | 53 | 4 |
100 rows × 8 columns
- いびつなクラス分け
# バラツキ最大のいびつなクラス分け data[1][0]
| 国語 | 数学 | 社会 | 理科 | 英語 | 合計 | 順位 | クラス番号 | |
|---|---|---|---|---|---|---|---|---|
| 74 | 20 | 82 | 68 | 22 | 99 | 291 | 26 | 0 |
| 47 | 54 | 37 | 28 | 2 | 27 | 148 | 96 | 0 |
| 25 | 23 | 59 | 2 | 98 | 62 | 244 | 54 | 0 |
| 67 | 58 | 0 | 86 | 63 | 16 | 223 | 64 | 0 |
| 5 | 9 | 20 | 80 | 69 | 79 | 257 | 45 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 54 | 97 | 44 | 34 | 34 | 88 | 297 | 19 | 4 |
| 14 | 35 | 11 | 46 | 82 | 91 | 265 | 37 | 4 |
| 42 | 40 | 54 | 79 | 11 | 38 | 222 | 65 | 4 |
| 59 | 67 | 35 | 30 | 29 | 33 | 194 | 84 | 4 |
| 20 | 48 | 49 | 69 | 41 | 35 | 242 | 55 | 4 |
100 rows × 8 columns
# バラツキ最小のベストなクラス分けグラフ draw_graph(data[0][1], '5教科5クラス編成ベスト')
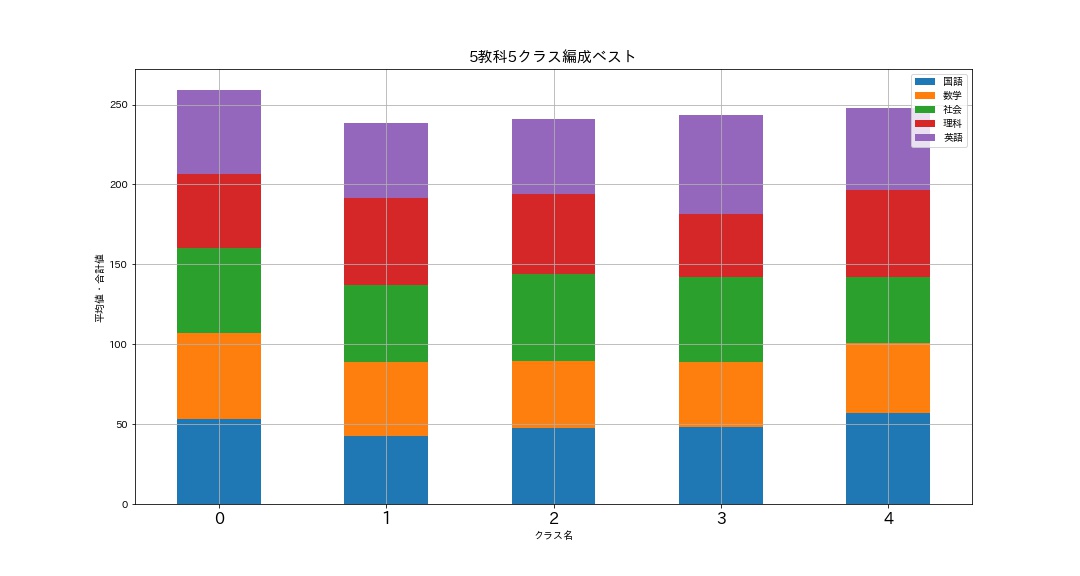
# バラツキ最大のワーストなクラス分けグラフ draw_graph(data[1][1], '5クラス編成ワースト')
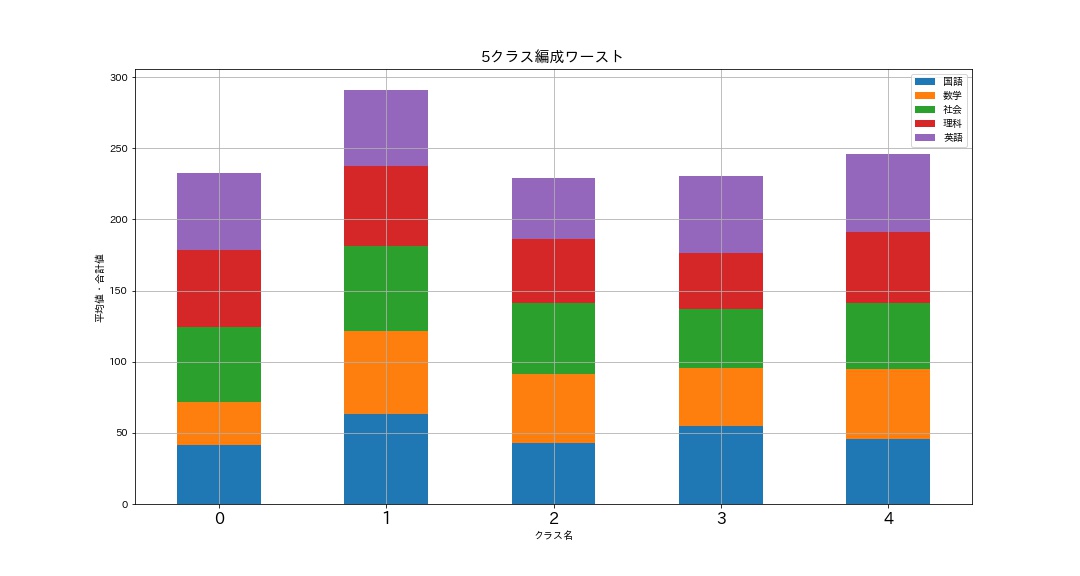
教科数と人数を増やして実行
5教科以外でも動くかどうか確認。
元の成績表を9教科にし、1000人に増やして確かめる。
# 9教科の成績表を1000人分生成する arr = np.random.randint(0,101,9000).reshape(1000, 9) # 成績表データフレームの作成 col = ["国語", "数学", "社会", "理科", "英語", '体育', '音楽', '美術', '家庭'] df_9 = pd.DataFrame(arr, columns=col) # 3行だけ表示 df_9
| 国語 | 数学 | 社会 | 理科 | 英語 | 体育 | 音楽 | 美術 | 家庭 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 68 | 80 | 15 | 6 | 72 | 66 | 40 | 47 | 52 |
| 1 | 51 | 3 | 80 | 30 | 72 | 6 | 2 | 91 | 7 |
| 2 | 24 | 90 | 5 | 54 | 50 | 36 | 54 | 21 | 22 |
| 3 | 62 | 63 | 58 | 80 | 59 | 27 | 48 | 86 | 3 |
| 4 | 30 | 82 | 80 | 14 | 79 | 91 | 70 | 41 | 12 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 995 | 44 | 93 | 16 | 45 | 29 | 96 | 12 | 7 | 69 |
| 996 | 92 | 15 | 52 | 94 | 67 | 93 | 98 | 87 | 24 |
| 997 | 26 | 62 | 74 | 5 | 41 | 78 | 28 | 10 | 70 |
| 998 | 37 | 18 | 83 | 6 | 7 | 55 | 20 | 22 | 45 |
| 999 | 58 | 11 | 14 | 29 | 5 | 27 | 8 | 41 | 88 |
1000 rows × 9 columns
# 実行 6クラス編成 data_9 = main(df_9, split_num=6) # 表示 print('最小標準偏差',data_9[0][2]) print('最大標準偏差',data_9[1][2])
最小標準偏差 1.6666133026238075
最大標準偏差 13.120630584238242
# バラツキ最小のベストなクラス分け data_9[0][0]
| 国語 | 数学 | 社会 | 理科 | 英語 | 体育 | 音楽 | 美術 | 家庭 | 合計 | 順位 | クラス番号 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 809 | 78 | 4 | 84 | 5 | 3 | 88 | 37 | 3 | 74 | 376 | 794 | 0 |
| 231 | 91 | 80 | 54 | 33 | 11 | 82 | 98 | 8 | 12 | 469 | 408 | 0 |
| 853 | 20 | 80 | 9 | 60 | 33 | 45 | 82 | 47 | 93 | 469 | 408 | 0 |
| 226 | 29 | 50 | 71 | 15 | 14 | 99 | 78 | 81 | 93 | 530 | 182 | 0 |
| 770 | 8 | 98 | 92 | 49 | 37 | 75 | 80 | 8 | 4 | 451 | 497 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 713 | 91 | 86 | 48 | 6 | 37 | 85 | 74 | 65 | 27 | 519 | 212 | 5 |
| 828 | 85 | 57 | 67 | 88 | 46 | 5 | 47 | 79 | 35 | 509 | 240 | 5 |
| 24 | 49 | 43 | 38 | 74 | 28 | 4 | 5 | 2 | 81 | 324 | 915 | 5 |
| 140 | 72 | 71 | 40 | 81 | 39 | 65 | 53 | 60 | 35 | 516 | 220 | 5 |
| 565 | 41 | 80 | 3 | 48 | 24 | 34 | 32 | 14 | 28 | 304 | 939 | 5 |
1000 rows × 12 columns
# バラツキ最大のいびつなクラス分け data_9[1][0].head()
| 国語 | 数学 | 社会 | 理科 | 英語 | 体育 | 音楽 | 美術 | 家庭 | 合計 | 順位 | クラス番号 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 664 | 8 | 64 | 53 | 28 | 60 | 56 | 15 | 75 | 29 | 388 | 745 | 0 |
| 399 | 50 | 3 | 41 | 78 | 54 | 100 | 41 | 84 | 70 | 521 | 205 | 0 |
| 874 | 92 | 65 | 17 | 73 | 15 | 98 | 76 | 66 | 71 | 573 | 87 | 0 |
| 130 | 63 | 57 | 60 | 18 | 6 | 61 | 63 | 57 | 37 | 422 | 626 | 0 |
| 593 | 66 | 42 | 56 | 1 | 63 | 43 | 5 | 83 | 56 | 415 | 649 | 0 |
# バラツキ最小のベストなクラス分けグラフ draw_graph(data_9[0][1], '9教科6クラス編成ベスト')
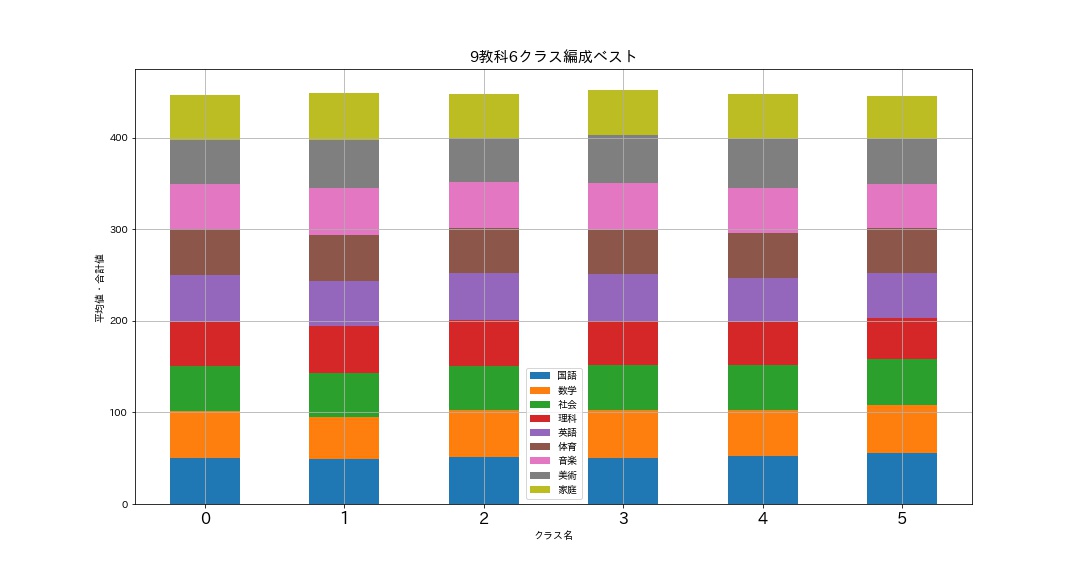
# バラツキ最大のワーストなクラス分けグラフ draw_graph(data_9[1][1], '9教科6クラス編成ワースト')
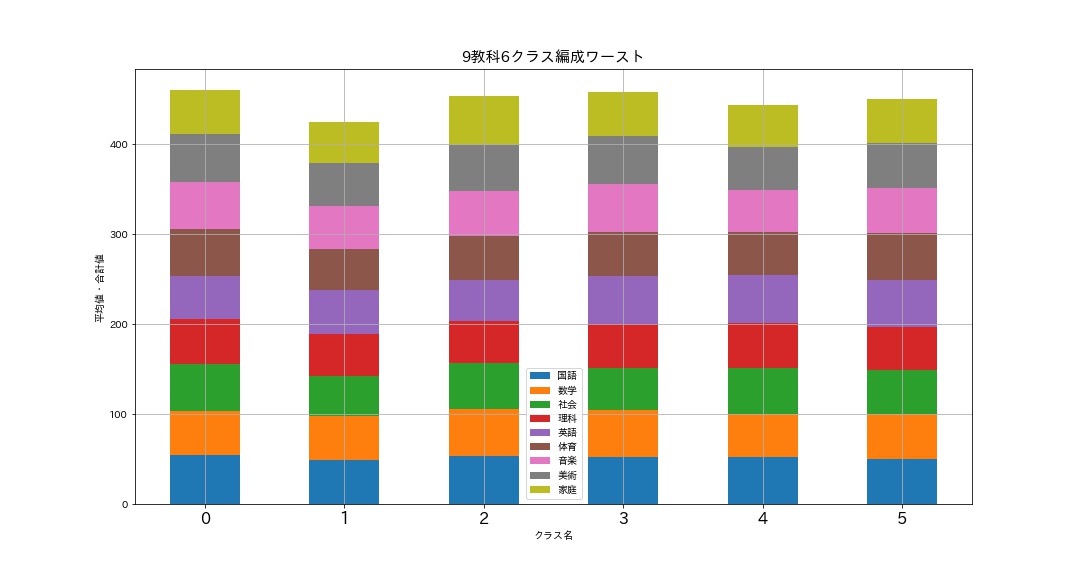
おわりに
任意の教科数と人数の入った成績表のデータフレームをランダムでシャッフルし、指定のクラス数に編成するプログラムができた。100回試行のうち最もバラツキの少ない編成と最も大きい編成とを抽出できる。
最終的にどういう値をどういう型で返す関数を作るのかを先にある程度決めておかないと、どうにでもなるというか、作りながら適当にやっているので締まりのない物が出来てしまう。そういうものしか作れないというのもあるけど。設計は大事ですね。それと想定外の使い方がされた場合の対処も。今回のは全く未対応。ドキュメントも適当。後で見返したら使い方わからんだろうw
気まぐれで始めてしまったものの大して面白くないシリーズをこの回で終わりにしますが、Pandasのグラフ機能を使うと積み上げ棒グラフがとても簡単に描けることと、リストが何でもかんでも入って便利だと分かったのは収穫でございました。
以上です。