【matplotlib】年代別の年間死亡者数とコロナ死亡者数を棒グラフと円グラフで描く
今回は、年代別で新型コロナの死亡者数と年間の死亡者数をグラフの作成をしながら比較して見る。
matplotlibでの棒グラフと円グラフ、pandasでの積み上げ棒グラフの練習を兼ねて。
新型コロナは騒動当初から「重症化傾向や死亡者は高齢者、さらには基礎疾患のひとが多い」と言われてきた。コロナのデータを見ても確かにそのようになっている。しかしそれは別にコロナに限ったことではなく、年間を通した死亡者数は高齢者のほうが多い。
年間の年代別死亡者と、新型コロナの年代別死亡者をそれぞれグラフ化することによって、改めてその傾向を見てみる。
【実行環境】
- Windows10 WSL:Ubuntu
- Anaconda
- Python3.8
- Jupyter Notebook
- ライブラリ
- pandas、matplotlib、japanize-matplotlib(豆腐文字化け回避の日本語表示用:個人的事情)
# インストール $ pip install pandas matplotlib japanize-matplotlib
目次
使用するデータ(3つ)
- 人口統計、年代別死亡者数
- 新型コロナの年代別死亡者数
- 新型コロナの累計死亡者数
- 厚生労働省オープンデータ
death_total.csv
- 厚生労働省オープンデータ
人口動態統計年報 年齢階級別にみた死亡数
「人口動態統計年報 主要統計表(最新データ、年次推移)」というページからExcelにコピペしたデータを使う。
import pandas as pd import matplotlib.pyplot as plt import japanize_matplotlib # データファイル (元は厚生労働省のデータ fname = '年次・年齢階級別の死亡者数.xlsx' df = pd.read_excel(fname) df = df.rename(columns={'Unnamed: 0':'年齢階級'}) df
| 年齢階級 | 1985 | 1990 | 1995 | 2000 | 2005 | 2007 | 2008 | 2009 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0~4 | 10834 | 7983 | 7040 | 5269 | 4102 | 3809 | 3747 | 3460 |
| 1 | 5~9 | 1791 | 1377 | 1235 | 738 | 655 | 552 | 557 | 534 |
| 2 | 10~14 | 1649 | 1242 | 1184 | 744 | 590 | 534 | 516 | 487 |
| 3 | 15~19 | 4212 | 4353 | 3362 | 2397 | 1802 | 1599 | 1621 | 1467 |
| 4 | 20~24 | 4669 | 4795 | 5087 | 4035 | 3370 | 3049 | 2977 | 2960 |
| 5 | 25~29 | 4725 | 4277 | 4596 | 4817 | 4170 | 3641 | 3622 | 3561 |
| 6 | 30~34 | 6733 | 5038 | 5129 | 5596 | 5952 | 5410 | 5282 | 4931 |
| 7 | 35~39 | 11127 | 8551 | 6839 | 7046 | 7469 | 7679 | 7690 | 7786 |
| 8 | 40~44 | 15884 | 15311 | 12814 | 10479 | 10238 | 10064 | 10034 | 10375 |
| 9 | 45~49 | 22707 | 21728 | 24136 | 19736 | 15754 | 14966 | 14674 | 14584 |
| 10 | 50~54 | 35851 | 30258 | 32946 | 35843 | 28964 | 24562 | 23321 | 22686 |
| 11 | 55~59 | 45575 | 47541 | 44732 | 45992 | 49579 | 49777 | 46146 | 41934 |
| 12 | 60~64 | 50845 | 62728 | 68310 | 60680 | 62258 | 58505 | 60767 | 61606 |
| 13 | 65~69 | 64730 | 69931 | 89089 | 89058 | 80829 | 80094 | 80491 | 82052 |
| 14 | 70~74 | 95991 | 89813 | 102443 | 116528 | 120825 | 116667 | 115785 | 109527 |
| 15 | 75~79 | 121250 | 127523 | 125428 | 131000 | 159362 | 159772 | 163351 | 159471 |
| 16 | 80~84 | 123573 | 139549 | 157863 | 147060 | 174185 | 188314 | 198991 | 201406 |
| 17 | 85~89 | 86351 | 111120 | 134363 | 148980 | 165385 | 173407 | 183113 | 189913 |
| 18 | 90~94 | 34768 | 52814 | 72295 | 90913 | 127573 | 134751 | 140585 | 139746 |
| 19 | 95~99 | 7772 | 12355 | 19831 | 29230 | 50503 | 58983 | 64764 | 67799 |
| 20 | 100歳以上 | 825 | 1569 | 2780 | 4789 | 9578 | 11678 | 13837 | 14949 |
| 21 | 総数 | 752283 | 820305 | 922139 | 961653 | 1083796 | 1108334 | 1142407 | 1141865 |
年齢階級は5歳ずつに分けてある。年次は1985年~2009年まで飛び飛び。
年次別の年間死亡者と推移の棒グラフ
# データ y = (df.iloc[21,1:]/10000).tolist() # 万人単位にする為10000で割った x = list(map(str, df.columns[1:])) print('年次:',x) print('死亡者総数:',y)
年次: ['1985', '1990', '1995', '2000', '2005', '2007', '2008', '2009']
死亡者総数: [75.2283, 82.0305, 92.2139, 96.1653, 108.3796, 110.8334, 114.2407, 114.1865]
# 年次別の年間死亡者と推移 グラフ plt.figure(figsize=(15, 12)) plt.bar(x, y, width=0.6) plt.title('年次別の年間死亡者と推移', size=20) plt.xlabel('年次', size=15) plt.ylabel('年間死亡者総数(万人)', size=14) plt.xticks(size=15) plt.yticks(size=15) plt.grid() plt.savefig('年次別の年間死亡者と推移棒グラフ.jpg') plt.show()

年間の死亡者総数は上昇傾向。2009年の総数は114万1865人。2020年のデータはここには載っていないが138万4544人。
年次別の年齢階級ごとの積み上げ棒グラフ
年齢階級ごとの積み上げ棒グラフを、年次ごとに棒にする。
積み上げ棒グラフをmatplotlibで描くと面倒ですが、Pandasのグラフ機能を使うと比較的簡単に描けます。
行が一つの棒に積みあがるグラフになるので、下のコードではデータを転置させている。
# データ df_stacked = df.iloc[:-1, :] # 総数行以外に絞り込み df_stacked = df_stacked.set_index('年齢階級') # インデックスを置換 df_stacked = df_stacked.T # 行と列を転置 # 表示 df_stacked
| 年齢階級 | 0~4 | 5~9 | 10~14 | 15~19 | 20~24 | 25~29 | 30~34 | 35~39 | 40~44 | 45~49 | ... | 55~59 | 60~64 | 65~69 | 70~74 | 75~79 | 80~84 | 85~89 | 90~94 | 95~99 | 100歳以上 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1985 | 10834 | 1791 | 1649 | 4212 | 4669 | 4725 | 6733 | 11127 | 15884 | 22707 | ... | 45575 | 50845 | 64730 | 95991 | 121250 | 123573 | 86351 | 34768 | 7772 | 825 |
| 1990 | 7983 | 1377 | 1242 | 4353 | 4795 | 4277 | 5038 | 8551 | 15311 | 21728 | ... | 47541 | 62728 | 69931 | 89813 | 127523 | 139549 | 111120 | 52814 | 12355 | 1569 |
| 1995 | 7040 | 1235 | 1184 | 3362 | 5087 | 4596 | 5129 | 6839 | 12814 | 24136 | ... | 44732 | 68310 | 89089 | 102443 | 125428 | 157863 | 134363 | 72295 | 19831 | 2780 |
| 2000 | 5269 | 738 | 744 | 2397 | 4035 | 4817 | 5596 | 7046 | 10479 | 19736 | ... | 45992 | 60680 | 89058 | 116528 | 131000 | 147060 | 148980 | 90913 | 29230 | 4789 |
| 2005 | 4102 | 655 | 590 | 1802 | 3370 | 4170 | 5952 | 7469 | 10238 | 15754 | ... | 49579 | 62258 | 80829 | 120825 | 159362 | 174185 | 165385 | 127573 | 50503 | 9578 |
| 2007 | 3809 | 552 | 534 | 1599 | 3049 | 3641 | 5410 | 7679 | 10064 | 14966 | ... | 49777 | 58505 | 80094 | 116667 | 159772 | 188314 | 173407 | 134751 | 58983 | 11678 |
| 2008 | 3747 | 557 | 516 | 1621 | 2977 | 3622 | 5282 | 7690 | 10034 | 14674 | ... | 46146 | 60767 | 80491 | 115785 | 163351 | 198991 | 183113 | 140585 | 64764 | 13837 |
| 2009 | 3460 | 534 | 487 | 1467 | 2960 | 3561 | 4931 | 7786 | 10375 | 14584 | ... | 41934 | 61606 | 82052 | 109527 | 159471 | 201406 | 189913 | 139746 | 67799 | 14949 |
8 rows × 21 columns
df_stacked.columns
Index(['0~4', '5~9', '10~14', '15~19', '20~24', '25~29', '30~34', '35~39',
'40~44', '45~49', '50~54', '55~59', '60~64', '65~69', '70~74', '75~79',
'80~84', '85~89', '90~94', '95~99', '100歳以上'],
dtype='object', name='年齢階級')
df_stacked.index
Index([1985, 1990, 1995, 2000, 2005, 2007, 2008, 2009], dtype='object')
# 年次別の年代別死亡者総数 積み上げ棒グラフ作成 fig, ax = plt.subplots(figsize=(25,15)) # 積み上げ棒グラフ描画 df_stacked.plot.bar(y=df_stacked.columns, ax=ax, stacked=True) # タイトル等の設置と設定 plt.title('年次別の年代別死亡者総数積み上げ棒グラフ', size=28) plt.xlabel('年次', size=20) plt.ylabel('死亡者総数', size=20) plt.xticks(size=20, rotation=0) plt.grid() # グラフ保存 plt.savefig('年次別の年代別死亡者総数積み上げ棒グラフ.jpg') # 表示 plt.show()

グラフの真ん中に自動的に設置された凡例は上から順に年齢が若い。
一方、グラフは逆に上の方が高齢者。
2列ずつ足した年齢階級のデータを作成
年齢階級が5歳ずつで細かいので、2列ずつ加算していって階級数を半分にする。手作業で。
df_stacked.head(1)
| 年齢階級 | 0~4 | 5~9 | 10~14 | 15~19 | 20~24 | 25~29 | 30~34 | 35~39 | 40~44 | 45~49 | ... | 55~59 | 60~64 | 65~69 | 70~74 | 75~79 | 80~84 | 85~89 | 90~94 | 95~99 | 100歳以上 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1985 | 10834 | 1791 | 1649 | 4212 | 4669 | 4725 | 6733 | 11127 | 15884 | 22707 | ... | 45575 | 50845 | 64730 | 95991 | 121250 | 123573 | 86351 | 34768 | 7772 | 825 |
1 rows × 21 columns
# 2列ずつ足したデータを生成 df_stacked2 = pd.DataFrame() # 空のデータフレーム # 空データフレームに横に結合 df_stacked2 = pd.concat([ df_stacked.iloc[:, 0:2].sum(axis=1), df_stacked.iloc[:, 2:4].sum(axis=1), df_stacked.iloc[:, 4:6].sum(axis=1), df_stacked.iloc[:, 6:8].sum(axis=1), df_stacked.iloc[:, 8:10].sum(axis=1), df_stacked.iloc[:, 10:12].sum(axis=1), df_stacked.iloc[:, 12:14].sum(axis=1), df_stacked.iloc[:, 14:16].sum(axis=1), df_stacked.iloc[:, 16:18].sum(axis=1), df_stacked.iloc[:, 18:20].sum(axis=1), df_stacked.iloc[:, 20:22].sum(axis=1) ], axis=1) # カラム名の変更 df_stacked2 = df_stacked2.rename(columns={0:'0~9', 1:'10~19', 2:'20~29', 3:'30~39',4:'40~49', 5:'50~59',6:'60~69', 7:'70~79',8:'80~89',9:'90~99',10:'100歳以上'}) # 表示 df_stacked2
| 0~9 | 10~19 | 20~29 | 30~39 | 40~49 | 50~59 | 60~69 | 70~79 | 80~89 | 90~99 | 100歳以上 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1985 | 12625 | 5861 | 9394 | 17860 | 38591 | 81426 | 115575 | 217241 | 209924 | 42540 | 825 |
| 1990 | 9360 | 5595 | 9072 | 13589 | 37039 | 77799 | 132659 | 217336 | 250669 | 65169 | 1569 |
| 1995 | 8275 | 4546 | 9683 | 11968 | 36950 | 77678 | 157399 | 227871 | 292226 | 92126 | 2780 |
| 2000 | 6007 | 3141 | 8852 | 12642 | 30215 | 81835 | 149738 | 247528 | 296040 | 120143 | 4789 |
| 2005 | 4757 | 2392 | 7540 | 13421 | 25992 | 78543 | 143087 | 280187 | 339570 | 178076 | 9578 |
| 2007 | 4361 | 2133 | 6690 | 13089 | 25030 | 74339 | 138599 | 276439 | 361721 | 193734 | 11678 |
| 2008 | 4304 | 2137 | 6599 | 12972 | 24708 | 69467 | 141258 | 279136 | 382104 | 205349 | 13837 |
| 2009 | 3994 | 1954 | 6521 | 12717 | 24959 | 64620 | 143658 | 268998 | 391319 | 207545 | 14949 |
# 年次別の年代別死亡者総数 積み上げ棒グラフ作成 fig, ax = plt.subplots(figsize=(25,15)) # 積み上げ棒グラフ df_stacked2.plot.bar(y=df_stacked2.columns, ax=ax, stacked=True) # タイトル等 plt.title('年次別の年代別死亡者総数積み上げ棒グラフ', size=28) plt.xlabel('年次', size=20) plt.ylabel('死亡者総数', size=20) plt.xticks(size=20, rotation=0) plt.grid() # 画像保存 plt.savefig('年次別の年代別死亡者総数積み上げ棒グラフ2.jpg') # 表示 plt.show()

凡例は上から若い順、棒グラフは上から高齢者。天に近い。
ピンクの60~69歳以上の年齢階級までが棒のほとんどを占めている。
2009年の年代別死亡者総数の棒グラフ
今度は、データの最新年次の2009年を見る。
横軸:年齢階級、縦軸:死亡者総数の棒グラフを描く。
# 2009年のデータ pd.DataFrame(df_stacked2.iloc[-1, :])
| 2009 | |
|---|---|
| 0~9 | 3994 |
| 10~19 | 1954 |
| 20~29 | 6521 |
| 30~39 | 12717 |
| 40~49 | 24959 |
| 50~59 | 64620 |
| 60~69 | 143658 |
| 70~79 | 268998 |
| 80~89 | 391319 |
| 90~99 | 207545 |
| 100歳以上 | 14949 |
# 2009年の年代別棒グラフ # データ label = df_stacked2.columns y_data = df_stacked2.iloc[-1, :].values # グラフ描画 plt.figure(figsize=(18,15)) plt.bar(label, y_data, color='purple') plt.title('2009年の年代別死亡者総数', size=25) plt.xlabel('年代', size=20) plt.ylabel('死亡者総数', size=20) plt.xticks(size=20) plt.grid() plt.savefig('2009年の年代別死亡者総数棒グラフ.jpg') plt.show()

平均寿命の定義は、「その年に生まれた子が何歳まで生きるか」つまり余命。その年に亡くなった方の平均年齢ではない。測定値ではなく、予測値。
日本の平均寿命が延びた大きな要因は、上下水道の完備だそうだ。新生児の死亡数が激減した。我が町では江戸時代にヨーロッパ人が持ち込んだ感染症が流行った際に水路の完備を行ったりしている。水は大切。
2009年の年代別死亡者総数の円グラフ
上の棒グラフを円グラフのパーセンテージで表す。
# 2009年の年代別円グラフ #データ data = df_stacked2.iloc[-1, :].values # データ label = df_stacked2.columns # ラベル名 # 円グラフ描画 plt.figure(figsize=(15,15)) plt.pie( x=data, # データ labels=label, # ラベルの設置 autopct='%1.1f%%', # パーセント表示のオンとフォーマット設定 startangle=90, # スタート位置を0時から ) # タイトル設置 plt.title('2009年の年代別 年間死亡者総数 円グラフ', size=20) # ラベルのフォントサイズ plt.rcParams['font.size'] = 18 # 保存 plt.savefig('2009年の年代別死亡者総数円グラフ.jpg') # 表示 plt.show()

数値や文字が重なって見えないところがあるが、直し方がわからないのでそのままにしている。
matplotlibの円グラフは、デフォルトで時計の3時から右回りになっている。そのためplt.pie()の引数startangleで0時からに変更した。
外国では3時から右回りが円グラフの当たり前な描き方なのか?と思って海外メディアの円グラフの画像を検索したが、特にそうではない。直交座標の象限を利用してあるのか?と思ったが、それなら左回りになるでしょうし。
円グラフのスタートはデータの最終行から始まっている。ということは、0時スタートに変更したが、直交座標の象限通りにデータの最上行から左回りで描画されているとも考えられる。これだな。
コロナの年代別死亡者数
データは東洋経済オンラインのdemography.csvというファイル。年代別のコロナのデータが入っている。
データの期間は不明。たぶん2020年3月ぐらいから現在2021年7月28日までの、1年以上の累計。
# コロナの年代別死亡者データ (元は東洋経済オンライン fname = 'demography.csv' # csvファイル読込 df_demo = pd.read_csv(fname) df_demo
| year | month | date | age_group | tested_positive | hospitalized | serious | death | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2021 | 7 | 28 | 10歳未満 | 30813 | 2547 | 0 | 0 |
| 1 | 2021 | 7 | 28 | 10代 | 68613 | 5034 | 0 | 0 |
| 2 | 2021 | 7 | 28 | 20代 | 201758 | 14380 | 0 | 9 |
| 3 | 2021 | 7 | 28 | 30代 | 134145 | 9810 | 1 | 29 |
| 4 | 2021 | 7 | 28 | 40代 | 130003 | 10374 | 27 | 116 |
| 5 | 2021 | 7 | 28 | 50代 | 114826 | 9348 | 65 | 317 |
| 6 | 2021 | 7 | 28 | 60代 | 70864 | 6192 | 100 | 990 |
| 7 | 2021 | 7 | 28 | 70代 | 60251 | 5884 | 137 | 3076 |
| 8 | 2021 | 7 | 28 | 80代以上 | 58905 | 5390 | 79 | 8346 |
| 9 | 2021 | 7 | 28 | 不明 | 10574 | 1237 | 5 | 317 |
ワクチン接種が始まる前までは、20代は2,3人だったのに。ワクチン死。
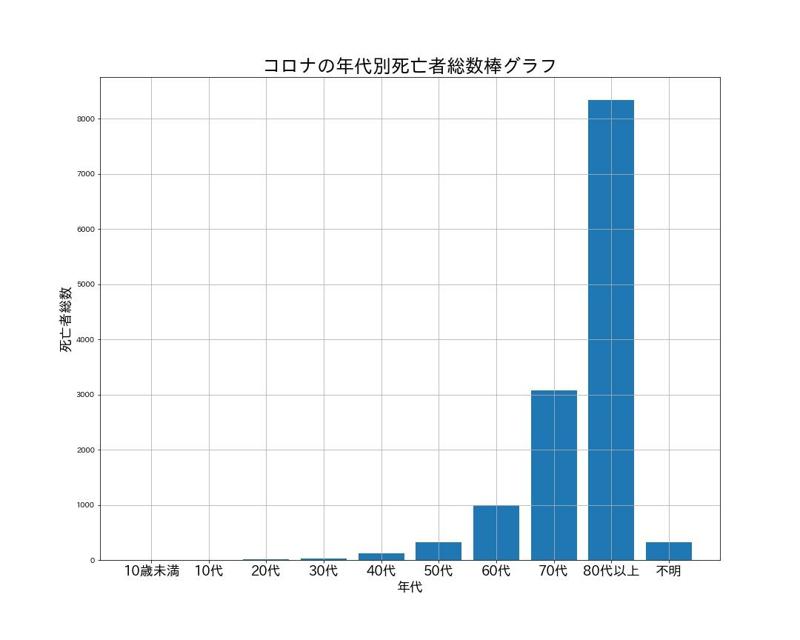
コロナの年代別死亡者総数 棒グラフ
横軸:age_group、縦軸:deathで棒グラフを描く。
# 棒グラフ描画 # データ x = df_demo['age_group'] y = df_demo['death'] # 描画 plt.figure(figsize=(15,12)) plt.bar(x, y) # タイトル等 plt.title('コロナの年代別死亡者総数棒グラフ', size=25) plt.xlabel('年代', size=18) plt.ylabel('死亡者総数', size=18) plt.xticks(size=18) plt.grid() # 保存 plt.savefig('コロナの年代別死亡者総数棒グラフ.jpg') # 表示 plt.show()
コロナの年代別死亡者総数 円グラフ
# コロナの年代別円グラフ #データ label = df_demo['age_group'] # ラベル名 data = df_demo['death'] # データ # 円グラフ描画 plt.figure(figsize=(15,15)) plt.pie( x=data, # データ labels=label, # ラベルの設置 autopct='%1.1f%%', # パーセント表示のオンとフォーマット設定 startangle=90, # スタート位置を0時から ) # タイトル設置 plt.title('コロナの年代別死亡者総数円グラフ', size=20) # ラベルのフォントサイズ plt.rcParams['font.size'] = 18 # 保存 plt.savefig('コロナの年代別死亡者総数円グラフ.jpg') # 表示 plt.show()

これは、決定的に、高齢者寄りが顕著。
字の重なりの解消法がわからないので放置した。
# 年代別死亡者総数占有率 df_dtrate = pd.DataFrame([df_demo['age_group'], df_demo['death'], df_demo['death']/df_demo['death'].sum()]) print('60代~80代以上:', df_dtrate.iloc[1,:][6:9].sum()) df_dtrate
60代~80代以上: 12412
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| age_group | 10歳未満 | 10代 | 20代 | 30代 | 40代 | 50代 | 60代 | 70代 | 80代以上 | 不明 |
| death | 0 | 0 | 9 | 29 | 116 | 317 | 990 | 3076 | 8346 | 317 |
| death | 0.0 | 0.0 | 0.000682 | 0.002197 | 0.008788 | 0.024015 | 0.075 | 0.23303 | 0.632273 | 0.024015 |
コロナの月別死亡者集計
最後に、厚生労働省オープンデータdeath_total.csvを月別で集計し、棒グラフにする。
コロナの累計死亡者を日毎に変換
このデータは累計データになっているので、日毎に変換する。
import numpy as np # 厚労省オープンデータ コロナの死亡者数データ fname = 'death_total.csv' # CSVを日付インデックスにして読み込み df_total = pd.read_csv(fname, index_col=0, parse_dates=True) # 日毎に変換 df_d_daily = np.append(1, np.diff(df_total['死亡者数'])) # 死亡者数列を日毎に置換 df_total['死亡者数'] = df_d_daily # 死亡者数列名のカラム名を変更 df_total = df_total.rename(columns={'死亡者数':'死亡者数(日毎)'}) # 表示 df_total
| 死亡者数(日毎) | |
|---|---|
| 日付 | |
| 2020-02-14 | 1 |
| 2020-02-15 | 0 |
| 2020-02-16 | 0 |
| 2020-02-17 | 0 |
| 2020-02-18 | 0 |
| ... | ... |
| 2021-07-23 | 9 |
| 2021-07-24 | 8 |
| 2021-07-25 | 5 |
| 2021-07-26 | 8 |
| 2021-07-27 | 14 |
530 rows × 1 columns
月別で集計
Pandasのresample().sum()を使うと、時系列データの一定期間の集計が簡単にできる。
インデックスは日付列で。
# 月別で集計 mon_data = df_total.resample('m').sum() mon_data
| 死亡者数(日毎) | |
|---|---|
| 日付 | |
| 2020-02-29 | 5 |
| 2020-03-31 | 51 |
| 2020-04-30 | 359 |
| 2020-05-31 | 477 |
| 2020-06-30 | 81 |
| 2020-07-31 | 37 |
| 2020-08-31 | 285 |
| 2020-09-30 | 275 |
| 2020-10-31 | 195 |
| 2020-11-30 | 373 |
| 2020-12-31 | 1321 |
| 2021-01-31 | 2261 |
| 2021-02-28 | 2165 |
| 2021-03-31 | 1274 |
| 2021-04-30 | 1067 |
| 2021-05-31 | 2818 |
| 2021-06-30 | 1732 |
| 2021-07-31 | 369 |
月別集計データの棒グラフ
集計した月別データを棒グラフにする。
# 月別データから棒グラフ # データ data = mon_data['死亡者数(日毎)'].values label = mon_data.index # 棒グラフ plt.figure(figsize=(15,8)) plt.bar(label, data, width=15) # タイトル等 plt.title('コロナの死亡者数月別集計棒グラフ~2021-7-27まで', size=25) plt.xlabel('日付', size=18) plt.ylabel('人数', size=18) plt.xticks(size=18) plt.grid() # 保存と表示 plt.savefig('コロナの死亡者数月別集計棒グラフ~2021-7-27まで.jpg') plt.show()

冬が多いのは分かるが、2021年6月・7月 5月・6月の死亡者数の多さは不自然。高齢者がワクチン接種し始めたころだ。ワクチン死かな。
おわりに
日本では年間138万人以上が亡くなる(2020年)。その多くを寿命を迎えるお年頃の高齢者が占める。コロナにしても極端に高齢者に偏る。そして、コロナの年間死亡人数は全体の年間死亡者総数の1%未満。1年以上ワクチンがなくとも幸い死亡者はそこまで増えていない。
結局コロナ騒動は、少数の高齢者が風邪ひいてコロナウィルス由来の肺炎で亡くなったのをカウントして大騒ぎする政治的イベントだという疑念は晴れない。しかも国際的に行われている。
大人な方は、「シラケつつ乗る、これである。」でこんな馬鹿な騒動を傍観しているんでしょうか?
長くなりました、以上です。